SEO优化-robots
本文详细介绍了robots.txt的作用、语法、配置规则,同时针对搜索引擎爬虫的另外两种更为细粒度的规范Robots Meta、X-Robots-Tag进行说明。
什么是robots文件
Robots是站点与spider沟通的重要渠道,站点通过robots文件声明本网站中不想被搜索引擎抓取的部分或者指定搜索引擎只抓取特定的部分。
搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中声明 该网站中不想被搜索引擎抓取的部分或者指定搜索引擎只抓取特定的部分。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎抓取网站上所有内容,请勿建立robots.txt文件。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
并非所有的搜索引擎都严格遵循robots.txt协议。一些爬虫可能会忽视robots.txt文件中的指令,从而访问并索引您希望隐藏的页面。
robots.txt文件放在哪里
robots.txt文件应该放置在网站根目录下。举例来说,当spider访问一个网站时,首先会检查该网站中是否存在http://yourhost.com/robots.txt这个文件,如果 Spider找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围。
robots.txt语法
robots文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
1 | <指令>:<可选空格><指令值><可选空格> |
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干指令行。
在robots.txt文件中,有几种主要指令可以使用:
User-agent:指定特定的搜索引擎爬虫。
Allow:允许爬虫访问某个页面或目录。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。
例如
Allow:/hibaidu允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。Disallow:阻止爬虫访问某个页面或目录。这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。
例如
Disallow:/help禁止robot访问/help.html、/helpabc.html、/help/index.html;Disallow:/help/则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html;Disallow:说明允许robot访问该网站的所有url在”/robots.txt”文件中,至少要有一条Disallow记录。如果”/robots.txt”不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Crawl-delay:设置爬虫访问的延迟。
Sitemap:提供网站地图的链接,帮助爬虫更好地抓取网站。
其中,Allow、Disallow支持通配符、$来模糊匹配url。
- **\***:匹配0或多个任意字符
- **$**:匹配行结束符。
示例
Disallow: /? 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL。
以本站robots为例。
运行所有爬虫访问,但不允许访问以下目录
1 | User-agent: * |
站点地图
针对robots中的配置项sitemap,通过文章进行说明,参见:SEO优化-sitemap站点地图
robots生成器
可以使用站长工具来生成robots
robots.txt生成器 - robots.txt写法 - robots协议
如何测试robots.txt是否正确
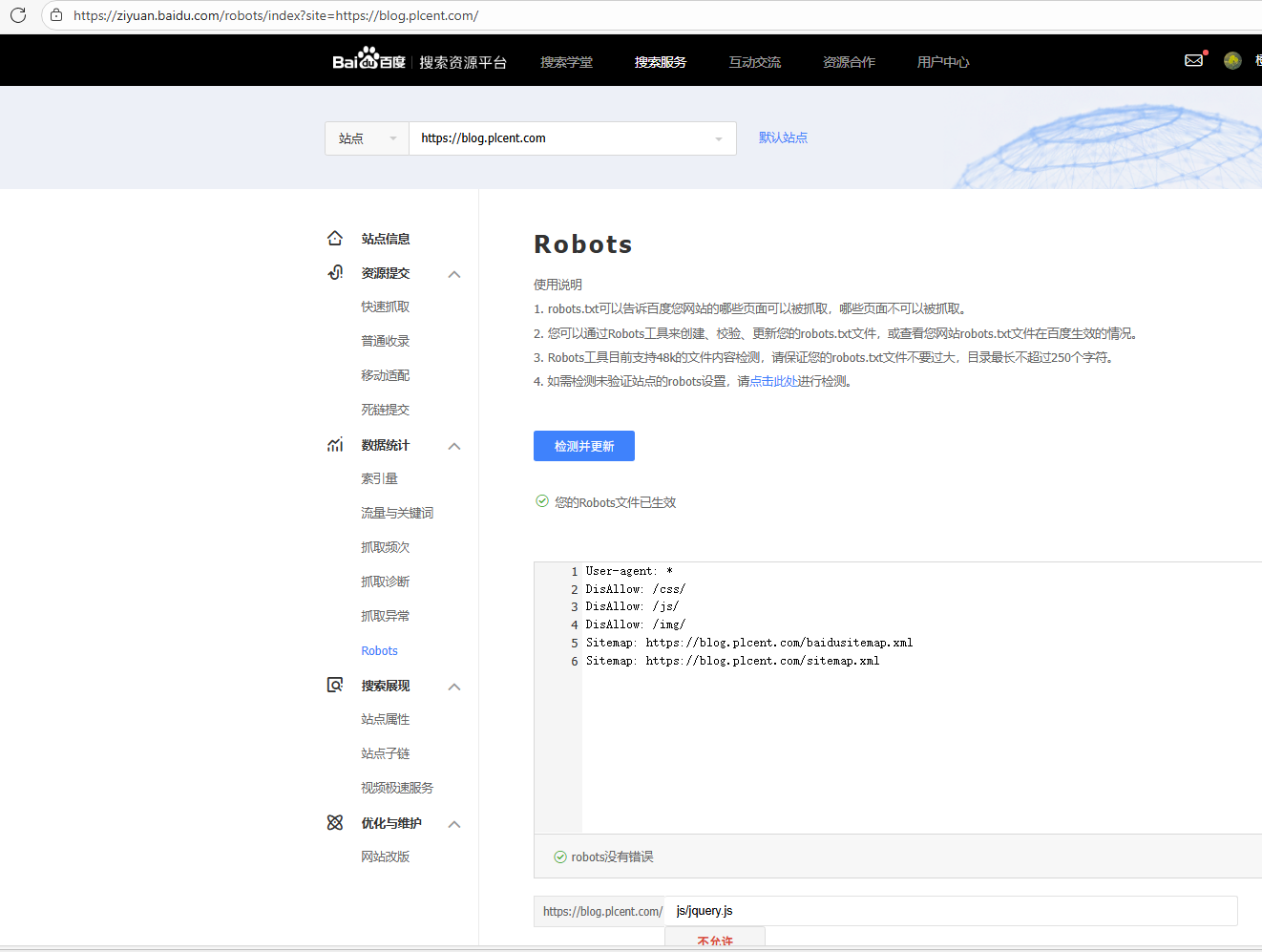
各大搜搜引擎都会提供检查工具,例如百度站长工具:Robots_robots文件检测工具_站长工具_网站支持_百度搜索资源平台中,提供了robots.txt测试工具,点击检测即可查看结果。
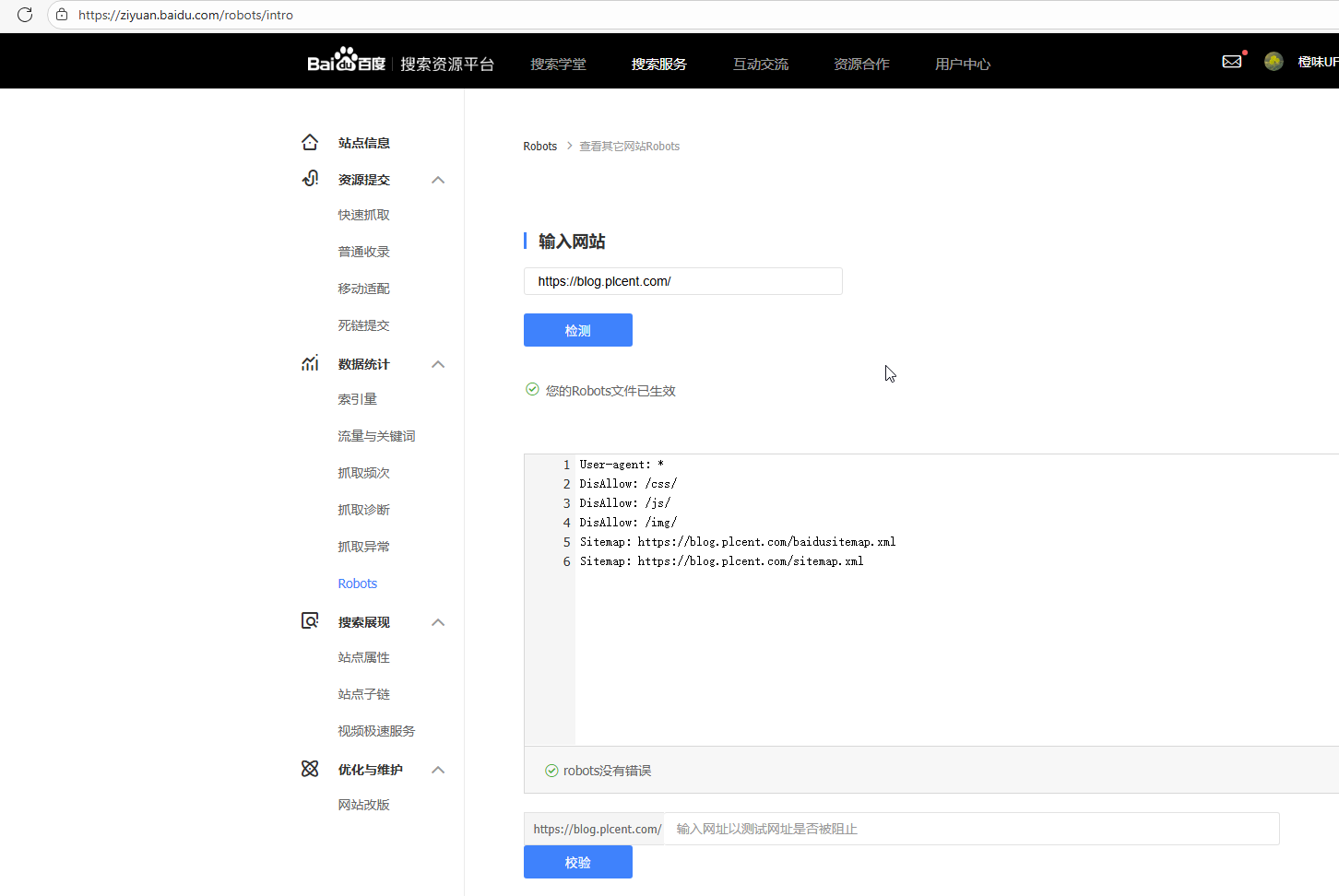
配置生效设置
在百度站长工具中,检测自己的站点的配置结果:https://ziyuan.baidu.com/robots/index
Robots Meta
Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而在html中的Robots Meta标签则主要是针对一个个具体的页面。
MDN中 html-meta中详细说明了该标签的用法: - HTML | MDN
语法
1 | <meta name="robots" content="<value>" /> |
content必须定义该属性,其值设置协作搜索引擎机器人的索引和抓取行为。 接受以下一个或多个关键字作为逗号分隔的列表:content
- index:允许机器人为页面编制索引。这是默认行为。 被所有主要爬虫使用
- noindex:请求机器人不为页面编制索引。 被所有主要爬虫使用
- follow:允许机器人点击页面上的链接。这是默认行为。 被所有主要爬虫使用
- nofollow:请求机器人不要点击页面上的链接。 被所有主要爬虫使用
- all 相当于
index, follow - none:
noindex, nofollow - noarchive:请求搜索引擎不缓存页面内容
- nosnippet:防止在搜索引擎结果中显示页面的任何描述
- noimageindex:请求此页面不显示为索引图像的引用页面
- nocache:
noarchive的同义词
示例
不允许爬虫点击网页上的链接,不允许爬虫为网页建立索引
1 | <meta name="robots" content="nofollow, noindex" /> |
X-Robots-Tag
X-Robots-Tag 响应头定义了爬虫应如何为 URL 编制索引。 虽然它不是任何规范的一部分,但它是与搜索机器人、网络爬虫和类似用户代理通信的事实上的标准方法。
该响应头和robots.txt、Robots Meta的区别是,X-Robots-TagHTTP 标头对于非 HTML 文档(如图像、PDF 或其他媒体)非常有用。
MDN中 X-Robots-Tag 中详细说明了该响应头的用法:X-Robots-Tag 标头 - HTTP |MDN
语法
1 | X-Robots-Tag: <indexing-rule> |
可选指定后续规则应应用于的用户代理:<bot-name>:
1 | X-Robots-Tag: <indexing-rule>, <bot-name>: <indexing-rule> |
indexing-rule 可以使用以下任何索引规则:
-
在搜索结果中编入索引或投放没有限制。 此规则是默认值,如果显式列出,则无效。
-
请勿在搜索结果中显示此页面、媒体或资源。 如果省略,则页面、媒体或资源可能会被编入索引并显示在搜索结果中。
-
请勿点击此页面上的链接。 如果省略,搜索引擎可能会使用页面上的链接来发现这些链接页面。
-
相当于 .
noindex, nofollow -
请勿在此页面的搜索结果中显示文本片段或视频预览。 静态图像缩略图(如果可用)可能仍然可见。 如果省略,搜索引擎可能会根据页面上找到的信息生成文本片段和视频预览。 要排除内容的某些部分不显示在搜索结果代码段中,请使用
data-nosnippetHTML 属性。 -
如果页面的内容通过 iframe 或类似的 HTML 元素嵌入到另一个页面中,则允许搜索引擎对页面内容进行索引,该规则, 只有当它伴随着
noindex值存在时才有效果。indexifembedded noindex -
最多使用字符数作为此搜索结果的文本片段。 如果未指定有效值,则忽略。
-
搜索结果中此页面的图片预览的图片尺寸大小。 如果省略,搜索引擎可能会显示默认尺寸的图像预览。 如果不希望搜索引擎使用较大的缩略图图像,请指定值
max-image-preview: standard
值包括:- none:不显示图像预览;
- standard:可能会显示默认图像预览;
- large:可能会显示更大的图像预览,直至视口的宽度。
-
在搜索结果中,最多使用秒数作为此页面上视频的视频片段。如果省略,搜索引擎可能会在搜索结果中显示视频片段,并由搜索引擎决定预览时长。如果未指定有效值,则忽略。
特殊值如下所示:- 0:根据设置,最多只能使用静态图像;
- -1:没有视频长度限制
-
请勿在搜索结果中提供此页面的翻译。 如果省略,搜索引擎可能会将搜索结果标题和代码片段翻译成搜索查询的语言。
-
请勿将此页面上的图像编入索引。 如果省略,页面上的图像可能会被索引并显示在搜索结果中。
unavailable_after: <date/time>请求在指定的
<date/time>之后不在搜索结果中显示此页面。 如果未指定有效值,则忽略。 必须以 RFC 822、RFC 850 或 ISO 8601 等格式指定日期。
默认情况下,内容没有到期日期。 如果省略,此页面可能会无限期地显示在搜索结果中。 爬虫预计会在指定日期和时间之后大幅降低网址的抓取速率。
示例
以下标头添加了 ,要求抓取工具不要在搜索结果中显示此页面、媒体或资源:
1 | HTTP/1.1 200 OK |
多个标头
以下响应有两个标头,每个标头都指定了索引规则:X-Robots-Tag
http复制
1 | HTTP/1.1 200 OK |
指定用户代理
可以指定规则应应用于哪个用户代理。 以下示例包含两个标头,它们要求不要点击此页面上的链接,并且虚构的爬虫不要为该页面编制索引或点击其上的任何链接:
1 | HTTP/1.1 200 OK |
在下面的响应中,定义了相同的索引规则,但在单个标头中。每个索引规则都适用于其后面指定的用户代理:
1 | HTTP/1.1 200 OK |
对于指定了多个爬虫和不同规则的情况,搜索引擎将使用否定规则的总和。例如:
googlebot: noindex, nofollow,others: nofollow
1 | X-Robots-Tag: nofollow |
优先级
当robots.txt、Robots Meta、X-Robots-Tag定义的优先级冲突时,采用更为严格的限制规则为准。
参见:X-Robots-Tag 标头 - HTTP |MDN
附录
官方参考资料:
网络教程:
SEO优化-robots

